📬 This is Part 1 of a 4-part series on shipping enterprise RAG. Originally published on my Substack. Read it there and subscribe for free → to get Parts 2–4 the moment they drop.
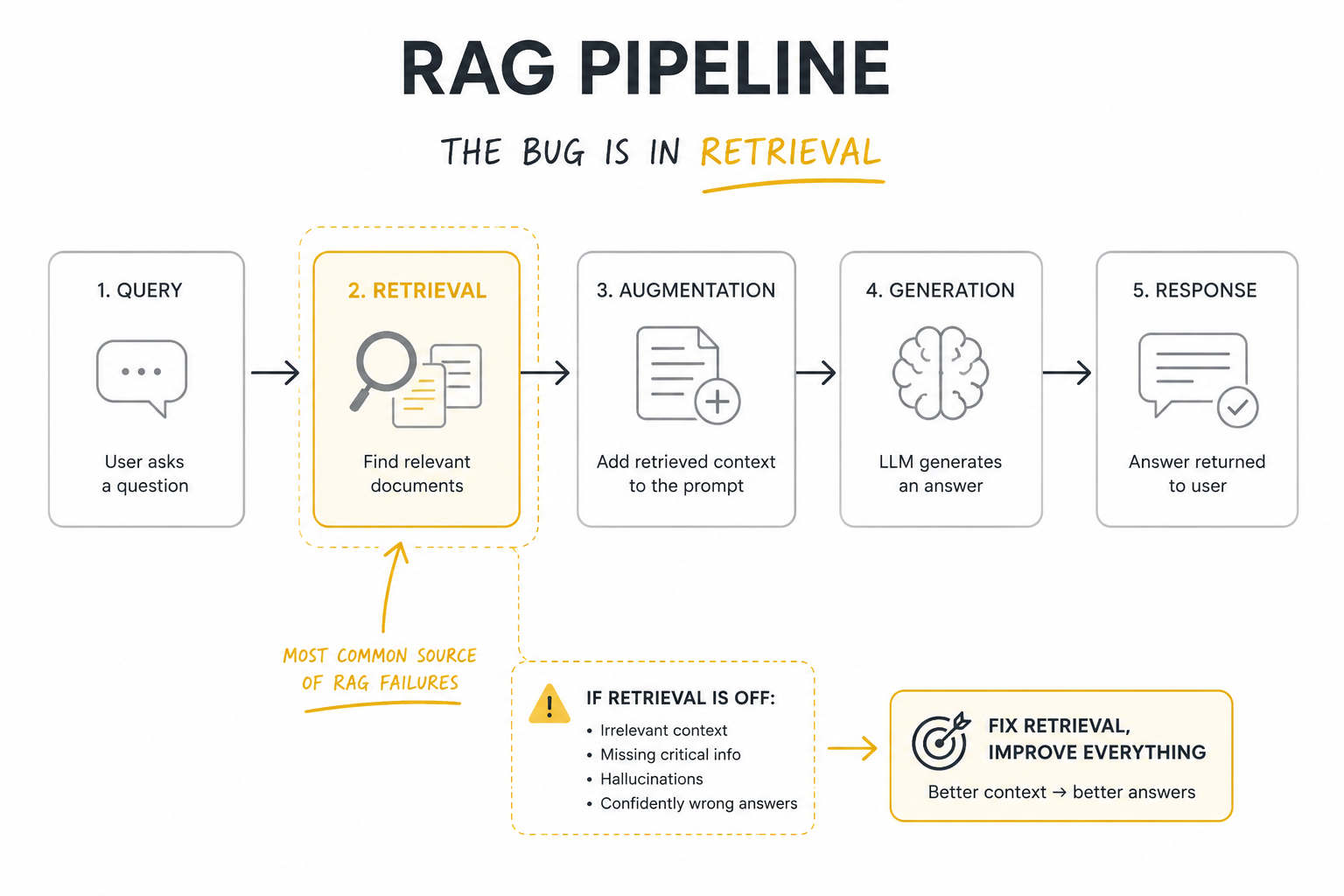 The RAG pipeline. When answers come back fluent but wrong, the bug usually lives in stage 2 — retrieval — not in the prompt or the model.
The RAG pipeline. When answers come back fluent but wrong, the bug usually lives in stage 2 — retrieval — not in the prompt or the model.
Last year I shipped a RAG assistant for a regulated enterprise: thousands of internal documents, hundreds of users, real compliance stakes. It held up in production, largely because I built it expecting the part that actually breaks to break.
Most RAG systems don’t get that benefit. They’re assembled from a tutorial, or scaffolded by an AI agent that confidently stands up a vector DB, embeds the corpus, runs top-k, and calls it done. That stack demos beautifully. Then it meets real questions and starts returning answers that are fluent, confident, and subtly wrong, and the team goes hunting for the bug in the wrong place.
I saw the same almost-right answer in testing. I asked about a specific policy clause and got back something plausible and quietly incorrect. In regulated work, almost is the dangerous failure mode: it’s wrong with the cadence of correct, and it survives a casual read.
The difference was where I looked next.
The reflexive move is to go fix the prompt. Tighten the instructions, add few-shot examples, drop the temperature, reach for a bigger model. I didn’t, because I already knew the prompt was almost never the cause. I went straight to the retrieval logs and pulled the exact chunks the system had been handed for that question.
The right chunk wasn’t there.
Not top-3. Not top-10. Not in the top 50. The relevant clause sat in the corpus, correctly indexed, and the retriever never surfaced it once. The model had done exactly what it’s built to do: answer from what it’s given. It was handed the wrong material and graded on the right essay. No prompt rewrite can fix that.
Why retrieval fails
This is the part the tutorials skip, and it’s where the real engineering lives.
The lexical–semantic gap. My clause was written in dense legal vocabulary; the question was plain English. Dense vector search captured the intent of the question well, but the chunk holding the answer used entirely different words and landed in a different region of the embedding space than the query. Semantically “near” documents kept winning; the actual answer kept losing. A lexical (keyword) search would have caught it on the first pass, because the chunk contained the exact phrase. The pipeline was pure embeddings, with no keyword channel at all. We’d have designed out the one retrieval mode that would have found it, if I hadn’t planned for it.
And the vocabulary gap is only the most visible failure. Retrieval breaks in at least three distinct ways, and a wrong answer can come from any of them:
-
The content never makes it into the index: bad extraction, a chunk boundary that splits the answer across two fragments so neither is self-contained, a table sliced mid-row.
-
The content is indexed but never ranks into the top-k for the query that needs it. That’s the case above.
-
The content is retrieved but lost when the context is assembled: buried among lower-relevance chunks, truncated, or drowned out.
Every one of these is upstream of the LLM. None is fixable in the prompt.
What the research says
This isn’t a quirk of my corpus. The most-cited study on the subject, Barnett et al., Seven Failure Points When Engineering a Retrieval-Augmented Generation System (2024), catalogs where these systems break in practice, and the failures people most often misdiagnose sit upstream of the LLM: in what gets indexed, what gets ranked, and what survives into the final context. When a RAG answer is wrong, the model often never saw the right material to begin with. I knew that going in, which is why I spent my effort on retrieval and treated the prompt as the last thing to touch, not the first.
The reframe
RAG isn’t fundamentally an LLM problem. The LLM is the cheap, swappable part. RAG is a retrieval problem with a generation step bolted on the end, and if retrieval is wrong, no prompt, no larger model, and no cleverer chain-of-thought will save you.
This is also the part you can’t outsource to a tutorial or an agent. A scaffolding tool will happily generate a working-looking pipeline, and it will be correct in the demo and wrong in production, because the decisions that determine whether the right chunk reaches the model are decisions about your documents: how they’re structured, where the answers actually live, how your users phrase questions versus how the source text is written. You can’t make those calls if you don’t understand what you’re building. The code is easy to generate. Knowing why it fails is the job.
What’s coming in this series
Over the next three articles I’ll walk through what made retrieval actually work, and what I’d do differently starting from scratch today.
-
Part 2: Your chunking strategy is probably wrong. Most production systems default to
RecursiveCharacterTextSplitterand quietly bleed accuracy. Four strategies that beat it, and a simple way to choose between them. -
Part 3: Hybrid retrieval and what actually moved the needle. BM25 + vector + reranking: the post I wish I’d read on day one, with real before/after numbers.
-
Part 4: The production reality check. Evaluation, observability, and cost: the unglamorous parts that decide whether a RAG system survives contact with real users.
If you’ve shipped RAG to production, or you’re about to, this series is for you.
Parts 2, 3, and 4 go deep on chunking, hybrid retrieval, and production evals. Subscribe for free on Substack → to get each one the moment it drops.